Original: http://protege.stanford.edu/publications/ontology_development/ontology101-noy-mcguinness.html
Наталя Ф. Ной і Дебора Л. Макгіннесс
Стенфордський університет, Стенфорд, Каліфорнія, 94305
[email protected] та [email protected]
1 Для чого потрібна онтологія?
В останні роки розвиток онтологій – явних формальних специфікацій термінів домену і відносин між ними (Грубер 1993) – перемістився з області лабораторій штучного інтелекту на робочі столи експертів із доменів. Онтологія стала звичайним явищем в Інтернеті. Онтології на веб-діапазоні від великих таксономиям категоризації веб-сайтів (наприклад, на Yahoo!) до категоризації товарів для продажу і їх особливості (наприклад, на сайті Amazon.com). Консорціум всесвітньої мережі (W3C) розробляє стандарт з опису ресурсів (Бріклі та Гуха 1999), мову для кодування знань на веб-сторінках, щоб зробити її зрозумілою для електронних агентів, які шукають інформацію. Агентство охоронних перспективних дослідницьких розробок (DARPA) разом з W3C розробляє мову розмітки агента DARPA (DAML) шляхом розширення RDF більш експресивними конструкціями, спрямованими на полегшення взаємодії агента в Інтернеті (Хендлер і Макгіннесс 2000). Багато дисциплін в даний час розробляють стандартні онтології, які експерти з доменів можуть спільно використовувати й анотувати інформацію на своєму домені. Медицина, наприклад, випустила великі, стандартні, структуровані словники, такі як SNOMED (Прайс і Спекмен 2000) і семантичної мережі єдиної системи медичної мови (Хамфріс і Ліндберг 1993). Широкі онтології загального призначення також з’являються. Наприклад, програма розвитку Організації Об’єднаних Націй і Dun & Bradstreet об’єднали свої зусилля для розробки онтології ССКТПООН, яка забезпечує термінологію для продуктів і послуг (www.unspsc.org).
Онтологія визначає загальний словник для дослідників, яким необхідно обмінюватися інформацією в домені. Вона включає в себе визначення машинно–інтерпретованих основних понять предметної області і відносин між ними.
Навіщо комусь хочуть розвивати онтологію? Деякі з причин:
� Для спільного використання загального поняття структури інформації серед людей або програмних агентів
� Щоб дозволити повторне використання знань у домені
� Щоб зробити припущення домену явним
� Щоб відокремити доменні знання від оперативних
� Щоб аналізувати доменні знання
Спільне використання загального розуміння структури інформації серед людей або програмних агентів – одна з найбільш загальних цілей розвитку онтологій (Мусен 1992; Грубер 1993). Наприклад, припустимо, що кілька різних веб-сайти містять медичну інформацію або надавати медичні послуги електронної комерції. Якщо ці веб-сайти обмінюватися і публікувати ту ж базову онтологію термінів, всі вони використовують, то комп’ютерні агенти можуть отримувати і узагальнену інформацію з цих різних сайтів. Агенти можуть використовувати цю зведену інформацію для відповідей на запити користувачів або як вхідні дані для інших додатків.
Дозвіл повторного використання знань у домені був однією з рушійних сил недавнього сплеску в області досліджень онтологій. Наприклад, моделі для багатьох різних областей необхідно представити поняття часу. Це уявлення включає в себе поняття тимчасових інтервалів, моментів часу, відносних заходів часу, і так далі. Якщо одна група дослідників розробляє таку онтологію в деталях, інші можуть просто повторно використовувати його для своїх доменів. Крім того, якщо нам потрібно побудувати великий онтологію, ми можемо інтегрувати кілька існуючих онтологій, що описують частини великий області. Ми також можемо повторно використовувати загальну онтологію, таку як онтологія ССКТПООН, і розширити його, щоб описати нашу область інтересів.
Створення явних припущень, що лежать в основі домену, реалізація дозволяє змінити ці припущення легко, якщо наші знання про зміни домену. Складне кодування припущень про світ в програмуванні код мови робить ці припущення не тільки складно знайти і зрозуміти, але важко змінити, зокрема, для кого-то без досвіду в області програмування. Крім того, явні специфікації знань в предметній області корисні для нових користувачів, які повинні дізнатися, які умови в області означають.
Відокремлення доменних знань від оперативних є ще одним поширеним використанням онтологій. Ми можемо описати завдання конфігурації продукту з його компонентів відповідно до необхідної специфікацією і впровадити програму, яка робить цю конфігурацію незалежної від продуктів і компонентів самих (Макгіннесс і Райт 1998). Після цього ми можемо розробити онтологію ПК-компонентів і характеристик і застосування алгоритму для налаштування зроблені на замовлення ПК. Ми також можемо використовувати той же алгоритм для конфігурування ліфтів, якщо ми “годувати” ліфта компонент онтологію до нього (Ротенфлу й ін. 1996).
Аналіз доменних знань можливий, як тільки декларативна специфікація термінів доступна. Формальний аналіз термінів надзвичайно цінно, коли обидві спроби повторного використання існуючих онтологій та поширити їх (Макгіннесс та ін. 2000).
Про це керівництво
Ми виконуємо свої розробки за допомогою Prot�g�-2000 (Protege 2000), Ontolingua (Ontolingua 1997), Chimaera (Chimaera 2000) як середовищ редагування онтологій. У цьому керівництві для прикладів ми використовуємо Prot�g�-2000.
Приклади про вино і їжу, які ми використовуємо в цьому посібнику, вільно на основі бази знань приклад, поданий у статті, яка описує CLASSIC – систему подання знань на основі логічного підходу опису (Брахман та ін. 1991). У довіднику із CLASSIC (Макгіннесс та ін. 1994) цей приклад набув подальшого розвитку. Prot�g�-2000 та інші фреймові системи описують онтології декларативно, конкретно вказавши, що ієрархії класів і до яких належать класи осіб.
Деякі онтологія-дизайнерські ідеї в цьому посібнику виникла з літератури на об’єктно-орієнтованого проектування (Румбау й ін. 1991; Бух та ін. 1997). Однак розробка онтологій відрізняється від проектування класів і відносин в об’єктно-орієнтованого програмування. Об’єктно-орієнтоване програмування центрів в основному навколо методів на класах-програміст робить дизайнерські рішення, засновані на операційних властивостях одного класу, в той час як онтологія дизайнер робить ці рішення, засновані на структурних властивостях класу. У результаті структура класу і відносини між класами в онтології відрізняються від структури подібної області в об’єктно-орієнтованої програми.
Це неможливо охопити всі питання, які розробник онтологія, можливо, доведеться боротися з і ми не намагаємося вирішити всі з них в цьому посібнику. Замість цього ми намагаємося дати відправну точку; початкове керівництво, яке допоможе новий дизайнер онтології для розробки онтологій. Зрештою, ми пропонуємо місця, щоб шукати пояснення більш складних структур і механізмів проектування, якщо домен вимагає від них.
І, нарешті, не існує єдино правильного методологія проектування онтології, і ми не намагалися визначити один. Ідеї, які ми представляємо тут, є ті, які ми знайшли корисним в нашому власному досвіді онтологій розвитку. В кінці цього керівництва ми пропонуємо список посилань на альтернативні методології.
2 Що таке онтологія?
У літературі штучного інтелекту містить безліч визначень онтології; багато з них суперечать один одному. Для цілей цього керівництва онтологія є формальним явне опис понять в області дискурсу (класів (іноді їх називають поняттями)), властивостей кожного поняття, що описує різні особливості і ознаки поняття (слотів (іноді називають ролями або властивостями) ), а також обмеження на слоти (фасети (іноді звані обмеження ролі)). Онтологія разом з набором індивідуальних прикладів класів утворює базу знань. Насправді, є тонка грань, де онтологія закінчується і починається база знань.
Класи знаходяться в центрі уваги більшості онтологій. Класи описують поняття в домені. Наприклад, клас вин представляє все вина. Конкретні вина є екземплярами цього класу. Вино Бордо в склі перед вами, коли ви читаєте цей документ є екземпляром класу вин Бордо. Клас може мати підкласи, які представляють собою поняття, які є більш конкретними, ніж суперкласу. Наприклад, ми можемо розділити клас всіх вин на червоне, біле і рожев� вина. В якості альтернативи ми можемо розділити клас всіх вин на ігристі і не ігристі вина.
Слоти описують властивості класів і прикладів: вино Ш�то Лафіт Ротшильд Поілак насичене; воно виробляється на винному заводі Ш�то Лафіт Ротшильд. У нас є два слоти, які описують вино в цьому прикладі: тіло слота зі значенням повної та слот виробника зі значенням Ш�то Лафіт Ротшильд. На рівні класу, ми можемо сказати, що екземпляри класу Вино будуть мати слоти, які висвітлюють їх аромат, тіло, рівень цукру, виробника вина і т.д.[1]
Усі екземпляри класу Вино і його підклас Поілак, мають слот виробник значення якого є екземпляром класу Винний завод (Рисунок 1). Всі екземпляри класу Винний завод мають слот виробляє, що відноситься до всіх винам (екземпляри класу Вино і його підкласів), що винний завод виробляє.
На практиці розробка онтології охоплює:
� визначення класів в онтології,
� організація класів у таксономічну (підклас-надклас) ієрархію,
� визначення слотів та опис допустимих значень для них,
� вставлення значень для слотів для прикладів.
Після цього ми можемо створити базу знань, визначивши окремі екземпляри цих класів заповнення певної інформації значення слот і додаткових обмежень тимчасових інтервалів.
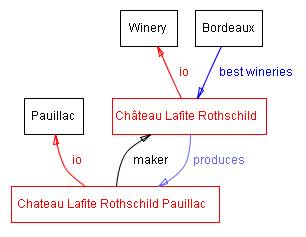
Рисунок 1. Деякі класи, екземпляри і відносини між ними в області вина. Ми використовували чорний для класів і червоний для примірників. Прямі посилання є слоти і внутрішні зв’язки, такі як екземпляр-з і підклас-з.
3 Проста методологія розробки знань
Як ми вже говорили раніше, немає жодного “правильний” шлях або методології розробки онтологій. Тут ми обговорюємо загальні питання, щоб розглянути і запропонувати один можливий процес розробки онтології. Ми описуємо ітеративний підхід до розробки онтології: ми починаємо з шорсткою першого проходу в онтологію. Потім ми переглянути і уточнити складається онтологію і заповнити в деталях. По дорозі, ми обговоримо моделювання рішень, які дизайнер повинен зробити, а також плюси, мінуси і наслідки різних рішень.
По-перше, ми хотіли б підкреслити деякі засадничі правила в області проектування онтології, до яких ми будемо називати багато разів. Ці правила можуть здатися досить догматичне. Вони можуть допомогти, проте, зробити проектні рішення в багатьох випадках.
1) Там не один правильний спосіб моделювання домен-завжди є життєздатні альтернативи. Краще рішення майже завжди залежить від програми, з якою ви маєте на увазі і розширень, які ви припускаєте.
2) Розвиток онтології – обов’язково ітеративний процес.
3) Поняття в онтології повинні бути близькі до об’єктів (фізичним або логічним) і відносинам у вашій області інтересів. Це, швидше за все, будуть іменники (об’єкти) або дієслова (відносини) в пропозиціях, які описують свій домен.
Тобто, вирішивши, що ми збираємося використовувати онтологію для, і, наскільки детально чи взагалі онтологія буде вестиме багато з рішень моделювання вниз по дорозі. Серед кількох життєздатних альтернатив, нам потрібно буде визначити, який з них буде працювати краще для проектованої завдання, бути більш інтуїтивним, більш розширюється і більш ремонтопрігодни. Ми також повинні пам’ятати, що онтологія є моделлю реальності світу і понять в онтології повинні відображати цю реальність. Після того, як ми визначимо початкову версію онтології, ми можемо оцінити і налагодити її, використовуючи її в додатках або методів вирішення завдань або шляхом обговорення з експертами в цій галузі, або обох. В результаті, ми майже напевно буде потрібно переглянути початкову онтологію. Цей процес ітеративного проектування, ймовірно, продовжиться протягом всього життєвого циклу онтології.
Крок 1. Визначення домену й області онтології
Ми пропонуємо почати розробку онтології з визначення її області і масштабу. Тобто відповісти на кілька основних питань:
� Для якого домену призначено онтологію?
� Для чого нам потрібна онтологія?
� Для запитань якого типу інформація в онтології має надати відповіді?
� Хто буде використовувати і вести онтологію?
Відповіді на ці питання можуть змінитися під час процесу проектування онтології, але в будь-який момент часу вони допомагають обмежити масштаб моделі.
Розглянемо онтологію вина та їжі, які ми представили раніше. Подання продуктів харчування і вин є областю онтології. Ми плануємо використовувати цю онтологію для додатків, які пропонують хороші поєднання вин і продуктів харчування.
Природно, що поняття, що описують різні типи вин, основні види їжі, поняття гарного поєднання вина і їжі і погана комбінація буде фігурувати в нашій онтології. У той же час, малоймовірно, що онтологія буде включати поняття для управління запасами на винному заводі або співробітників в ресторані, навіть якщо ці поняття якось пов’язані з поняттями вина та їжі.
Якщо онтологія, яку ми проектуємо, буде використовуватися для надання допомоги в обробці природної мови статей у винних журналах, це може бути важливо включити синоніми і частково з промови інформацію для понять в онтології. Якщо онтологія буде використовуватися, щоб допомогти клієнтам вирішити, ресторан, яке вино замовити, нам потрібно включити інформацію роздрібних цін. Якщо він використовується для винних покупців в запасаються винний льох, оптові ціни і наявність можуть бути необхідні. Якщо люди, які будуть підтримувати онтологію описують домен на мові, який відрізняється від мови користувачів онтології, ми, можливо, буде потрібно, щоб забезпечити відповідність між мовами.
Питання компетентності.
Один із способів визначити сферу онтології накидати список питань, які база знань грунтується на онтології повинні бути в змозі відповісти, питання компетенції (Грунінгер і Фокс 1995). Ці питання будуть служити лакмусовим папірцем пізніше: Чи містить онтологія досить інформації для відповіді на ці типи питань? Чи є відповіді вимагають певного рівня деталізації або подання певної області? Ці питання компетенції тільки ескіз і не повинні бути вичерпними.
У винному і харчовому доменах, є наступні можливі питання компетенції:
� Які характеристики вина слід враховувати при виборі вина?
� Бордо червоне чи біле вино?
� Чи добре смакує Каберне Совіньйон із морепродуктами?
� Який кращий вибір вина до смаженого м’яса?
� Які характеристики вина впливають на його придатність для блюда?
� Чи зазнає букет або тіло вина певних змін із класичним роком?
� Які хороші марочні вина для Напа Зінфандель?
Судячи з цього списку питань, онтологія буде включати інформацію про різні винних характеристиках і типах вина, марочні років-хороші і погані-класифікації товарів, які мають значення для вибору відповідного вина, рекомендується поєднання вина і їжі.
Крок 2. Розгляд повторного використання наявних онтологій
Це майже завжди варто врахувати, що хтось зробив і перевірки, якщо ми можемо уточнити і розширити існуючі джерела для нашої конкретної предметної області та завдання. Повторне використання існуючих онтологій може бути вимога, якщо наша система повинна взаємодіяти з іншими додатками, які вже скоєних конкретним онтологій або контрольованих словників. Багато онтології вже доступні в електронному вигляді і можуть бути імпортовані в середу розробки онтологій, які ви використовуєте. Формалізм, в якому онтологія виражається часто не має значення, так як багато систем уявлення знань можуть імпортувати і експортувати онтології. Навіть якщо система подання знань не може працювати безпосередньо з конкретним формалізму, завдання перекладу онтології з одного формалізму в іншій зазвичай не є складною.
Є бібліотеки повторно використовуваних онтологій в Інтернеті та в літературі. Наприклад, ми можемо використовувати бібліотеки онтологій Ontolingua (http://www.ksl.stanford.edu/software/ontolingua/) або DAML (http://www.daml.org/ontologies/). Є також цілий ряд загальнодоступних комерційних онтологій (наприклад, UNSPSC (www.unspsc.org), RosettaNet (www.rosettanet.org), DMOZ (www.dmoz.org)).
Наприклад, база знань французьких вин може вже існувати. Якщо ми можемо імпортувати цю базу знань і онтологію, на якій вона заснована, ми будемо мати не тільки класифікація французьких вин, а й перший прохід по класифікації вина характеристик, використовуваних для розпізнавання і опису вин. Списки властивостей вина вже можуть бути доступні з комерційних веб-сайтів, таких як www.wines.com, що клієнти вважають використовувати, щоб купити вина.
У цьому керівництві, проте ми будемо припускати, що немає відповідних онтологій вже не існує, і почати розробляти онтологію з нуля.
Крок 3. Перерахування важливих термінів в онтології
Корисно записати список всіх термінів, які ми хотіли б щось робити заяви про те чи пояснити користувачеві. Які умови, які ми хотіли б поговорити? Які властивості означають ці терміни мають? Що б ми хотіли б сказати про ці термінах? Наприклад, важливі винні пов’язані терміни будуть включати в себе “вино”, “виноград”, “винний завод”, “місце розташування”, “колір” винний, в “тіло”, “смак” і “вміст цукру”; різні види “їжі”, такі як “риба” і “червоне м’ясо”; підтипи вина, такі як “біле вино”, і так далі. Спочатку, важливо, щоб отримати повний список термінів, не турбуючись про перекриття між поняттями, які вони представляють, відносини між термінами, або будь-яких властивостей, які поняття можуть мати, або поняття є класами або слотами.
Наступні два кроки розвивається ієрархії класів і визначення властивостей понять (слотів) -Є тісно пов’язані між собою. Це важко зробити одну з них, а потім робити інший. Як правило, ми створюємо кілька визначень понять в ієрархії, а потім продовжити, описуючи властивості цих понять і так далі. Ці два кроки є також найбільш важливі кроки в процесі проектування онтології. Ми опишемо їх тут коротко, а потім провести наступні два розділи обговорюють більш складні питання, які необхідно враховувати, поширені помилки, рішення, щоб зробити, і так далі.
Крок 4. Визначення класів та ієрархії класів
Є кілька можливих підходів при розробці ієрархії класів (Ушолд і Грунінгер 1996):
� Зверху вниз процес розробки починається з визначення найзагальніших понять предметної області і подальшої спеціалізації понять. Наприклад, ми можемо почати з створення класів для загальних понять “вина” і “їжі”. Тоді ми спеціалізуємося “Клас вина”, створюючи деякі з його підкласів: “Біле вино”, “Червоне вино”, “Рожев� вино”. Далі ми можемо класифікувати клас “Червоне вино”, наприклад, на “Сіра”, “Червоне Бургундське“, “Каберне Совіньйон” і так далі.
� Процес розробки знизу вгору починається з визначення самих конкретних класів, листя ієрархії, з наступною угрупованням цих класів в більш загальних понять. Наприклад, ми почнемо з визначення класів для “Поілак” і “Маргокс” вин. Потім ми створюємо загальний суперклас для цих двох класів – “Медок” – що, у свою чергу, є підкласом “Бордо”.
� Процес розробки поєднання являє собою поєднання зверху вниз і знизу вгору підходи: Ми визначаємо більш помітні поняття, а потім узагальнити і спеціалізуватися їх відповідним чином. Ми могли б почати з кількох понять вищого рівня, таких як “Вино”, і кілька конкретних понять, таких як “Маргокс”. Потім ми можемо співвіднести їх з поняттям середнього рівня, таким як “Медок”. Тоді ми можемо захотіти згенерувати всі регіональні класи вина з Франції, тим самим створюючи ряд понять середнього рівня.
Рисунок 2 відображає можливий прорив серед різних рівнів узагальнення.
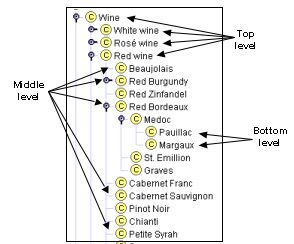
Рисунок 2. Різні рівні таксономії вин: “Вино”, “Червоне вино”, “Біле вино”, “Рожев� вино” – більш загальні поняття, верхній рівень. “Поілак” і “Маргокс” – більш вузькі класи ієрархії, нижчий рівень.
Жоден з цих трьох методів не є за своєю природою краще, ніж будь-який з інших. Підхід взяти сильно залежить від особистого погляду на домен. Якщо розробник має систематичний вид зверху вниз домену, то це може бути простіше використовувати підхід зверху вниз. Комбінований підхід часто є найпростішим для багатьох розробників онтологій, так як поняття “в середині”, як правило, більш описові поняття в області (Рош 1978).
Якщо ви схильні вважати, що вина, виділивши найбільш загальну класифікацію, а потім зверху вниз підхід може працювати краще для вас. Якщо ви б швидше почати отримувати заземлений з конкретними прикладами, підхід знизу вгору може бути більш підходящим.
Який би підхід ми вибираємо, ми зазвичай починаємо з визначення класів. Зі списку, створеного на Кроці 3, ми вибираємо терміни, що описують об’єкти, що мають самостійне існування, а не точки, які описують ці об’єкти. Ці умови будуть класи в онтології і стануть якорями в ієрархії класів.[2] Ми організуємо класи в ієрархічну таксономії, задаючи якщо, будучи екземпляром одного класу, об’єкт буде обов’язково (тобто за визначенням) примірником деякого іншого класу.
Якщо клас А є суперклас класу В, то кожен екземпляр В також є екземпляром
Іншими словами, клас В являє собою поняття, яке є “свого роду” А.
Наприклад, кожен Піно Нуар вино обов’язково червоне вино. Тому клас “Піно Нуар” є підклас класу “Червоне вино”.
Рисунок 2 відображає частину ієрархії класів для онтології вин. Розділ 4 містить докладне обговорення речей, щоб шукати при визначенні ієрархії класів.
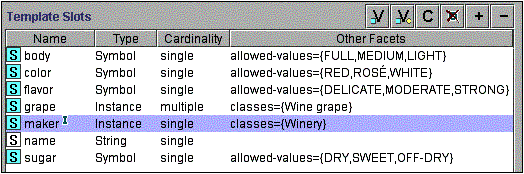
Рисунок 3. Слоти для класу “Вино” і фацети цих слотів. Значок “I” поруч зі слотом виробник вказує на те, що слот має зворотний (Розділ 5.1)
Крок 5. Визначення властивостей класів — слоти
Класи самі по собі не дають достатньо інформації, щоб відповісти на питання компетенції з Кроку 1. Після того, як ми визначили деякі класи, ми повинні описати внутрішню структуру понять.
Ми вже вибрали класи зі списку термінів, який ми створили на Кроці 3. Більшість залишилися термінів, ймовірно, будуть властивостями цих класів. Ці терміни включають, наприклад, “колір”, “тіло”, “смак” і “вміст цукру” в винному і “розташування” виноробні.
Для кожної властивості в списку, ми повинні визначити, до якого класу він описує. Ці властивості стають слоти, прикріплені до класів. Таким чином, клас Вино буде мати такі слоти: “колір”, “тіло”, “смак” і “цукор”. А клас винзавод матиме слот “розташування”.
У цілому, існує кілька типів властивостей об’єктів, які можуть стати слоти в онтології:
� “внутрішні” властивості, такі як “смак” вина;
� “зовнішні” властивості, такі як “назва” й “область” походження вина;
� частини, якщо об’єкт структурований; вони можуть бути як фізичні, так і абстрактні “частини” (наприклад, курси їжі)
� ставлення до інших особам; це відносини між окремими членами класу та інших елементів (наприклад, “виробник” вина, що представляє відношення між вином і виноробнею, а також “винограду”, з якого вино виготовляється).
Таким чином, на додаток до властивостей ми визначили раніше, нам потрібно додати такі слоти класу Вино: “назва”, “область”, “виробник”, “виноград”. На Рисунку 3 показані слоти для класу “Вино”.
Усі підкласи класу успадковують слот цього класу. Наприклад, всі слоти класу Вино будуть успадковані для всіх підкласів вина, включаючи червоне вино і біле вино. Ми додамо додатковий слот, рівень таніну (низький, середній або високий), до класу червоного вина. Слот рівень таніну буде успадкований усіма класами, котрі представляють червоні вина (такі як “Бордо” і “Божоле”).
Проріз повинна бути додана в найзагальнішому класі, який може мати ця властивість. Наприклад, тіло і колір вина повинна бути додана в класі вина, так як це самий загальний клас, екземпляри якого будуть мати тіло і колір.
Крок 6. Визначення фасетів слотів
Слоти можуть мати різні аспекти, що характеризують тип значення, дозволені значення, число значень (по потужності), а також інші особливості значень слота можуть прийняти. Наприклад, значення слота ім’я (як в “ім’я вина”) є одним рядком. Тобто, ім’я слот з типом значення String. Слот виробляє (як в “винний завод виробляє ці вина») може мати кілька значень і значення є екземплярами класу Вино. Тобто, виробляє слот з типом значення Instance з вином як дозволеного класу.
Тепер ми опишемо кілька загальних граней.
Кардинальність слота
Слот кардинальне визначає, скільки значень слот може мати. Деякі системи розрізняють тільки між однією потужності (що дозволяє не більше ніж одне значення) і множинної потужності (що дозволяє будь-яке число значень). Тіло вина буде один слот кількість елементів (вино може мати тільки одне тіло). Вина, вироблені конкретної виноробні заповнити слот множинний виробляє для класу винзавод.
Деякі системи дозволяють визначити будь-якої мінімальної і максимальної потужності, щоб описати кількість значень слота більш точно. Мінімальна потужність N означає, що слот повинен мати принаймні N значень. Наприклад, виноградна слоті Вино має мінімальну потужність 1: кожне вино виготовляється принаймні одного сорту винограду. Максимальна потужність М означає, що слот може мати не більше значень M. Максимальна кількість елементів для слота винограду для одиночних сортових вин становить 1: ці вина виробляються тільки з одного сорту винограду. Іноді це може бути корисно, щоб встановити максимальну потужність в 0. Цей параметр буде означати, що слот не може мати значення для конкретного підкласу.
Слот – тип значення
Значення типу фасет описує, які типи значень можна заповнити слот. Нижче наведено список з найбільш поширених типів значень:
� Рядок – це найпростіший тип значення, яке використовується для слотів, таких як назва: значенням є проста рядок
� Число (іноді більш конкретні типи значень флоат і Integer використовуються) описує слоти з числовими значеннями. Наприклад, ціна вина може мати тип значення з плаваючою точкою
� Булеві слоти не є простими так-ні прапорів. Наприклад, якщо ми обираємо не представляти ігристі вина як окремий клас, чи ні вино ігристе може бути представлено у вигляді значення булевої слота: якщо значення “істина” (“так”) вино ігристе і якщо значення “брехня” (“ні”) вино не ігристе один.
� Перелічуваних слоти вказати список конкретних дозволених значень слота. Наприклад, ми можемо вказати, що слот смак може взяти на себе одну з трьох можливих значень: сильний, помірний, і ніжний. У Prot�g�-2000 перелічувані слоти типу “Символ”.
� Слоти типу приклад дозволяють визначення відносин між людьми. Слоти з типом значення Інстанції повинні також визначити список дозволених класів, з яких екземпляри можуть прийти. Наприклад, слот виробляє для класу Winery може мати екземпляри класу Вино як його цінності.[3]
Рисунок 4 відображає визначення слота “виробляє” у класі “Винний завод”.
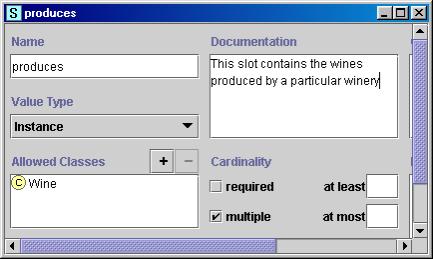
Рисунок 4. Визначення слота виробляє, який описує вина, вироблені на винному заводі. Слот має потужність, тип кратне значення Instance, і клас Вино як допустимий клас для його значень.
Домен і діапазон слота
Допустимі класи для слотів типу Instance часто називають діапазон слота. У прикладі на Рисунку 4 класу Вино є діапазон слота виробляє. Деякі системи дозволяють обмежити діапазон слота, коли роз’єм підключений до певного класу.
Класи, до якого приєднаний слот або через класи, властивість описує слот, називаються доменом слота. Клас Виноробство є областю слота виробляє. В системах, де ми надаємо слоти для класів, класів, до яких слот приєднаний зазвичай складають домен цього слоту. Там немає необхідності вказувати домен окремо.
Основні правила визначення домену і діапазон слот схожі:
При визначенні домену або діапазону для слота, знайти найбільш загальні класи або клас, який може бути, відповідно, домен або діапазон для слотів.
З іншого боку, не визначити домен і діапазон, який є занадто загальне: всі класи в домені слота повинні бути описані слотом і екземплярами всіх класів в діапазоні слот повинен бути потенційними наповнювачі для слот. надмірно загальний клас для діапазону (тобто один не хотів би, щоб діапазон РІЧ), але можна було б хотіти вибрати клас, який буде охоплювати всі наповнювачі
Замість того, щоб перерахувати всі можливі підкласи класу Вино для діапазону слота виробляє, просто список вин. У той же час, ми не хочемо, щоб вказати діапазон слота як РІЧ найбільш загальний клас в онтології.
Більш конкретно:
Якщо список класів, що визначають діапазон або домен слота включає клас і його підклас, видаліть підклас.
Якщо діапазон слота містить і клас Вино і клас Червоне вино, ми можемо видалити Червоне Вино з діапазону, так як він не додає ніякої нової інформації: Червоне вино є підкласом вина і тому діапазон слот вже неявно включає його, а також всі інші підкласи класу “Вино”.
Якщо список класів, що визначають діапазон або домен слота містить всі підкласи класу А, але не сам клас А, діапазон повинен містити тільки клас А, а не підкласи.
Замість визначення діапазону слота включити червоне вино, біле вино, і рожеве вино (перераховуючи всі прямі підкласи вина), ми можемо обмежити діапазон до самого класу “Вино”.
Якщо список класів, що визначають діапазон або домен слота містить всі, крім декількох підкласи класу А, подумайте, якщо клас А буде зробити більш відповідне визначення діапазону.
У системах, де є слот до класу таке ж, як при додаванні класу до домену слота, одні і ті ж правила застосовуються до прихильності слот: З одного боку, ми повинні спробувати зробити це якомога більш загальний. З іншого боку, ми повинні гарантувати, що кожен клас, до якого ми надаємо слот дійсно може мати властивість, яке представляє слот. Ми можемо прикріпити слот рівень таніну до кожного з класів, що представляють червоні вина (наприклад, Бордо, Мерло, Божоле і т.д.). Однак, так як всі червоні вина мають властивість таніну рівня, ми повинні замість того, щоб прикріпити слот до цього більш загального класу червоних вин. Узагальнюючи домен слота рівень таніну додатково (шляхом приєднання його до класу Вино замість цього) нічого очікувати правильним, так як ми не використовуємо рівень таніну для опису білих вин, наприклад.
Крок 7. Створення прикладів
Останнім кроком є створення окремих екземплярів класів в ієрархії. Визначення окремого екземпляра класу потрібно (1) вибрати клас, (2) створення окремого примірника цього класу, і (3) заповнення значень слотів. Наприклад, ми можемо створити окремий екземпляр Шато-Моргон-Божоле, щоб представити певний тип Божоле вина. Шато-Моргон-Божоле є екземпляром класу Божоле, що представляє всі вина Божоле. Цей екземпляр визначив наступні значення слотів (Рисунок 5):
� Тіло: світле
� Колір: червоний
� Смак: м’який
� Рівень таніну: низький
� Виноград: Гамай (приклад класу “Виноград для вина”)
� Виробник: Шато-Моргон (приклад класу “Винний завод”)
� Область: Божоле (приклад класу “Регіон-вина”)
� Цукор: сухий
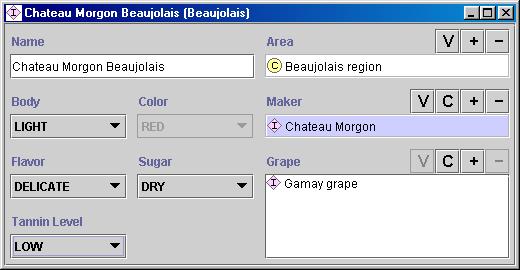
Рисунок 5. Визначення екземпляра класу Божоле. Примірник Шато Моргон Божоле з регіону Божоле, виробленого з винограду Гамі по виноробні Шато Моргон. Він має легкий корпус, тонкий аромат, колір червоний, і низький рівень таніну. Це сухе вино.
4 Визначення класів та ієрархії класів
У цьому розділі обговорюються речі, які потрібно подивитися і виправити помилки, які легко зробити при визначенні класів і ієрархії класів (Крок 4 з Розділу 3). Як ми вже відзначали раніше, немає єдиного правильного ієрархії класів для будь-якого заданого домену. Ієрархія залежить від можливих способів застосування онтології, рівня деталізації, який необхідний для застосування, особистих уподобань, а іноді і вимоги до сумісності з іншими моделями. Проте, ми обговоримо кілька керівних принципів, щоб мати на увазі при розробці ієрархії класів. Після визначення значної кількості нових класів, корисно стояти назад і перевірити, якщо формується ієрархія відповідає цим рекомендаціям.
4.1 Перевірка, чи правильна ієрархія класів
An “is-a” relation
Ієрархія класів являє собою “є різновидом” відносини: клас А підклас В, якщо кожен екземпляр В також є екземпляром А. Наприклад, Шардоне є підкласом білого вина. Ще один спосіб думати про таксономічних відношенні є як “доброї з” відносини: Шардоне є свого роду біле вино. Реактивного літака є свого роду повітряного судна. М’ясо є свого роду їжі.
Підклас класу представляє собою концепцію, яка є “свого роду” концепції, яка представляє суперкласу.
Одне вино не є підкласом всіх вин
Загальна помилка моделювання полягає в тому, щоб включати в себе як в однині та множині версію тієї ж концепції в ієрархії рішень колишній підклас останнього. Наприклад, було б неправильно визначити клас Вина і клас Вино як підклас вин. Після того, як ви думаєте про ієрархію як представляє “доброї з” відносин, помилка моделювання стає ясно: одне вино не є свого роду вина. Кращий спосіб уникнути такої помилки завжди використовувати або однини чи множини в назвах класів (див. Розділ 6 для обговорення про найменування понять).
Перехідність ієрархічних зв’язків
Відношення підкласу транзитивні:
Якщо B є підкласом А і С є підклас В, то С є підкласом А
Наприклад, ми можемо визначити клас Вино, а потім визначити клас Біле вино як підклас вина. Потім ми визначаємо клас Chardonnay як підклас білого вина. Транзитивність відносини підкласу означає, що клас Chardonnay також є підкласом вина. Іноді ми розрізняємо прямі і непрямі підкласи підкласів. Прямий підклас є “найближчим” підклас класу: немає класів між класом і його прямим подклассом в ієрархії. Тобто, немає ніяких інших класів в ієрархії між класом і його безпосереднього суперкласу. У нашому прикладі, Шардоне є прямим подклассом Біле вино і не є прямим подклассом вина.
Еволюція ієрархії класів
Підтримка ієрархії послідовного класу може стати складним завданням, як домени розвиватися. Наприклад, протягом багатьох років, все вина Зінфандель були червоними. Таким чином, ми визначаємо клас Зінфандель вин як підклас Червоного вина класу. Іноді, однак, винороби почали тиснути виноград і забрати кольору продукують аспекти винограду відразу, тим самим змінюючи колір одержуваного вина. Таким чином, ми отримуємо “Біле Зінфандель”, колір якого троянда. Тепер нам потрібно розбити клас Зінфандель на два класи Зінфандель-Білий Зінфандель і Червоного Зінфандель-і класифікувати їх як підкласи рожеве вино і Червоне вино відповідно.
Класи та їхні назви
Важливо розрізняти клас і його назву:
Класи представляють поняття в області, а не слова, які позначають ці поняття.
Ім’я класу може змінитися, якщо ми виберемо іншу термінологію, але сам термін представляє об’єктивну реальність в світі. Наприклад, ми можемо створити клас Креветки, а потім перейменувати його в Креветки-клас як і раніше являє собою таку ж концепцію. Відповідні комбінації вина, що згадані креветки страви повинні ставитися до страв з креветок. З практичної точки зору, таке правило слід завжди дотримуватися:
Синоніми для того ж поняття не уявляють різні класи
Синоніми просто різні назви для поняття або терміна. Тому ми не повинні мати клас з ім’ям Shrimp і клас під назвою креветка і, можливо клас під назвою Crevette. Швидше за все, є один клас, названий або креветка або креветка. Багато системи дозволяють зв’язати список синонімів, перекладів або імен уявлення з класом. Якщо система не дозволяє цього об’єднання, синонімів завжди можуть бути вказані в документації про клас.
Уникання циклів класів
Нам слід уникати циклів в ієрархії класів. Ми говоримо, що є цикл в ієрархії, коли певний клас А має підклас В і в той же час B є суперклас А. Створення такого циклу в ієрархії становить заявляється, що класи А і В еквівалентні: все екземпляри є екземплярами B і всі екземпляри в також випадки А. Дійсно, так як в підклас а, екземпляри всіх в повинні бути екземплярами класу А. так як а підклас в, екземпляри всіх а в також повинні бути екземплярами класу В.
4.2 Аналіз “записів-сестер” в ієрархії класів
“Записи-сестри” в ієрархії класів
“Записи-сестри” в ієрархії – класи, які є прямими підкласами одного і того ж класу (див. Розділ 4.1).
Усі записи-сестри в ієрархії (для тих, у кореня, за винятком) повинні бути на тому ж рівні спільності.
Наприклад, Біле вино і Шардоне не повинні бути підкласами одного і того ж класу (скажімо, вино). Біле вино більш загальне поняття, ніж Шардоне. Брати і сестри повинні представляти поняття, які потрапляють “за тією ж лінії” таким же чином, що ділянки ж рівня в книзі знаходяться на тому ж рівні спільності. У цьому сенсі вимоги до ієрархії класів аналогічні вимогам, що пред’являються до книги нарисів.
Однак поняття в корені ієрархії (які часто представляються у вигляді прямих спадкоємців деяких дуже загального класу, таких як річ) представляють собою основні підрозділи домену і не повинні бути аналогічні концепції.
Скільки це забагато і скільки замало?
Немає жорстких правил для числа прямих підкласів, які повинні мати клас. Тим не менш, багато добре структуровані онтології мають від двох до дюжини прямих підкласів. Таким чином, наступні два вказівки:
Якщо клас має тільки один прямий підклас може бути проблемою моделювання або онтологія не є повним.
Якщо є більше дюжини підкласів для даного класу, то додаткові проміжні категорії можуть бути необхідні.
Перший з цих двох правил аналогічний правилом верстки, що марковані списки ніколи не повинні мати тільки одну точку кулі. Наприклад, більшість червоних бургундських вин є винами К�т д’Ор. Припустимо, що ми хотіли представити тільки цей тип більшості бургундських вин. Ми могли б створити клас Red Burgundy і потім єдиний підклас Кот д’Ор (Рисунок 6a). Проте, якщо в нашому представленні червоні вина Бургундське та К�т д’Ор дійсно рівнозначні (усі червоні Бургундські вина є винами К�т д’Ор, а всі К�т д’Ор є червоними Бургундськими винами), створення класу Кот д’Ор не потрібне і не додає ніякої нової інформації до подання. Якби потрібно було додати К�т Шалоньє, дешевші за Бургундські з регіону на південь від К�т д’Ор, то ми створили б два підкласи класу Бургундські: Кот д’Ор і Кот Шалоньє (Рисунок 6б).
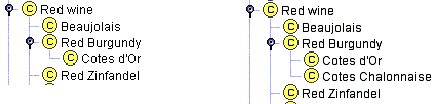
Рисунок 6. Підкласи класу “Червоне Бургундське”. Наявність одного підкласу класу, як правило, вказує на проблеми в моделюванні.
Припустимо тепер, що ми перерахувати всі типи вин, як прямі підкласи класу Вино. Цей список буде потім включати такі загальніші види вина як Божоле і Бордо, а також більш конкретні типи, такі як Паулік і Маргокс (Рисунок 7a). Клас Вино занадто багато прямих підкласів і, дійсно, для онтологія, щоб відобразити різні типи вина в більш організованою манері, Медок повинен бути підкласом Бордо і Cotes d’Or має бути підкласом Бургундії. Крім того, маючи такі проміжні категорії, як червоне вино і біле вино також буде відображати концептуальну модель предметної області вин, що багато людей (Рисунок 7б).
Проте, якщо ніякі природні класи не існують понять групи в довгому списку братів і сестер, немає необхідності створювати штучні класи, просто залишити класів, як вони є. Зрештою, онтологія є відображенням реального світу, і якщо не категоризації не існує в реальному світі, то онтологія повинна відображати це.
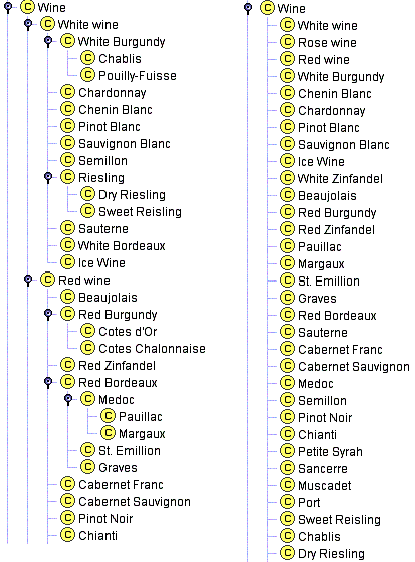
Рисунок 7. Категоризація вина. Маючи всі вина і види вина в порівнянні з кількома рівнями категоризації.
4.3 Множинне успадкування
Більшість систем уявлення знань дозволяють множинне успадкування в ієрархії класів: клас може бути підкласом декількох класів. Припустимо, що ми хотіли б створити окремий клас десертних вин, клас десертного вина. Вина Порт є як червоне вино і десертне вино.[4] Таким чином, ми визначаємо порт класу мати два суперкласу: Червоне вино і десертне вино. Всі екземпляри класу Port будуть екземплярами як класу Червоного вина і класу десертного вина. Клас Port успадкує слоти і їх межі з обох своїх батьків. Таким чином, він успадкує значення СОЛОДКЕ для слота цукру з класу десертного вина і слот рівні таніну і значення для його колірного слота від Червоного класу вина.
4.4 Коли вводити новий клас (чи ні)
Одна з найважчих рішень, щоб зробити при моделюванні, коли ввести новий клас або коли представляти відмінність за допомогою різних значень властивостей. Важко орієнтуватися як надзвичайно вкладену ієрархію з великою кількістю сторонніх класів і дуже плоску ієрархію, яка має дуже мало класів з дуже великою кількістю інформації, закодованої в слоти. Знаходження належного балансу, хоча це не так просто.
Є кілька емпіричних правил, які допомагають вирішити, коли вводити нові класи в ієрархії.
Підкласи класу, як правило (1) мають додаткові властивості, що суперклас не має, або (2) обмеження, відмінні від тих, з суперкласу, або (3) брати участь в різних відносинах, ніж суперкласу
Червоні вина можуть мати різні рівні таніну, тоді як ця властивість не використовується для опису вин в цілому. Значення цукру пазу десертного вина солодкий, в той час як це не відноситься до суперклас класу десертного вина. Піно Нуар вина можуть добре поєднуються з морепродуктами в той час як інші червоні вина не роблять. Іншими словами, ми вводимо новий клас в ієрархії, як правило, тільки тоді, коли є щось, що ми можемо сказати про це класі, що ми не можемо сказати про суперкласу.
З практичної точки зору, кожен підклас повинен або мати нові слоти додані до нього, або нові значення слотів, визначених чи перевизначити деякі аспекти для успадкованих слотів.
Проте, іноді це може бути корисно створити нові класи, навіть якщо вони не уводять ніяких нових властивостей.
Класи в термінологічних ієрархії не повинні вводити нові властивості
Наприклад, деякі онтології включають великі опорні ієрархії загальних термінів, які використовуються в домені. Наприклад, онтологія, що лежить в основі електронної системи медико-записи може включати в себе класифікацію різних захворювань. Ця класифікація може бути тільки що-ієрархія термінів, без властивостей (або з тим же набором властивостей). У цьому випадку, як і раніше корисно організувати терміни в ієрархії, а не плоский список, так як він буде (1) дозволяє легше дослідження і навігацію і (2) дають можливість лікарю легко вибрати рівень спільності терміна, який підходить для ситуації.
Ще одна причина, щоб вводити нові класи без будь-яких нових властивостей для моделювання понять, серед яких експерти в предметної області зазвичай роблять відмінність навіть якщо ми вирішили не моделювати саме відмінність. Так як ми використовуємо онтології для сприяння комунікації між експертами в предметній області, а також між експертами в предметній області і систем, заснованих на знаннях, ми хотіли б, щоб відобразити думку експерта домену в онтології.
Нарешті, ми не повинні створювати підкласи класу для кожного додаткового обмеження. Наприклад, ми ввели класи Червоне вино, біле вино, і рожеве вино, тому що ця різниця є природним в винному світі. Ми не вводили класи для делікатного вина, помірне вино, і так далі. При визначенні ієрархії класів, наша мета полягає в тому, щоб знайти баланс між створенням нових класів корисно для класової організації і створення надто багато класів.
4.5 Новий клас чи значення властивості?
При моделюванні предметної області, ми часто повинні вирішити, чи слід моделювати конкретну відмінність (наприклад, біле, червоне або рожев� вино) як значення властивості або як набір класів, знову-таки залежить від сфери області та завдання.
Чи повинні ми створити клас Біле вино або ж ми просто створюємо клас Вино і заповнити різні значення для кольору слота? Відповідь на це питання, як правило, знаходиться в області, які ми визначили для онтології. Наскільки важливо поняття Біле вино в нашій області? Якщо вина мають лише другорядне значення в області і чи дійсно вино біле не має яких-небудь особливих наслідків для його відносин до інших об’єктів, то ми не повинні вводити окремий клас для білих вин. Для моделі предметної області, використовуваної в заводу з виробництва винних етикеток, правила для винних етикеток будь-якого кольору однакові, а різниця не дуже важливо. В якості альтернативи, для подання вина, їжі, і їх відповідні комбінації червоне вино сильно відрізняється від білого вина: він пов’язаний з різними продуктами, володіє різними властивостями, і так далі. Крім того, колір вина важливий для бази знань вина, які ми можемо використовувати, щоб визначити, дегустації вин замовлення. Таким чином, ми створюємо окремий клас для білого вина.
Якщо поняття з різними значеннями слота стають обмеженнями для різних слотів в інших класах, то ми повинні створити новий клас для розрізнення. В іншому випадку, ми представляємо відмінність в значенні слота.
Точно так же наше вино онтологія має такі класи як Червоне Merlot і Біле Merlot, а не єдиний клас для всіх вин Merlot: червоні Мерло і білі Merlots дійсно різні вина (зроблені з того ж винограду), і якщо ми розробляємо докладну онтологію вино, це відмінність важливо.
Якщо різниця має важливе значення в області, і ми думаємо, що об’єкти з різними значеннями для відмінності різних видів об’єктів, то ми повинні створити новий клас для розрізнення.
З огляду на потенційні окремі екземпляри класу також можуть бути корисними при прийнятті рішення про те, чи слід вводити новий клас.
Клас, до якого належить окремий примірник, не повинен часто змінюватися.
Зазвичай, коли ми використовуємо здавлення ззовні, а не внутрішні властивості понять для диференціації між класами, екземпляри цих класів повинні часто мігрують з одного класу в інший. Наприклад, Охолоджене вино не повинно бути класом в онтології, яка описує пляшки вина в ресторані. Властивість охолоджене має бути просто атрибутом вина в пляшці, так як екземпляр Охолоджене вино може легко перестати бути примірником цього класу, а потім став екземпляр цього класу знову.
Зазвичай числа, кольору, місця розташування є значеннями слотів і не призводять до створення нових класів. Вино, однак, є помітним виключенням, так як колір вина настільки першорядне значення для опису вина.
Як інший приклад розглянемо людську анатомію-онтологію. Коли ми представляємо ребра, ми створюємо клас для кожного з “1-го лівого ребра”, “2-е ліве ребро”, і так далі? Або у нас є клас Ребро з прорізами для замовлення і бічного положення (зліва направо)?[5] Якщо інформація про кожного з ребер, які ми представляємо в онтології, істотно відрізняється, то ми дійсно повинні створити клас для кожного ребра. Тобто, якщо ми хочемо, щоб представити дані суміжності і інформацію про місцезнаходження (яка відрізняється для кожного ребра), а також специфічні функції, які кожне ребро Плай та органи воно захищає, ми хочемо класи. Якщо ми моделюємо анатомію в дещо меншій мірі спільності, і все ребра дуже схожі, наскільки наші потенційні додатки стурбовані (ми просто говоримо про те, які ребра розбивається на X-Ray без наслідків для інших частин тіла) , ми хочемо, щоб спростити нашу ієрархію і мають тільки клас Ребро з двома слотами: бічне положення, порядок.
4.6 Приклад чи клас?
Ухвалення рішення про конкретну концепції є класом в онтології або окремого примірника залежить від того, що потенційні додатки онтології є. Рішення, де класи кінця і окремі екземпляри починають починається з рішення, що є найнижчим рівнем деталізації в поданні. Рівень деталізації в свою чергу, визначається потенційним застосуванням онтологій. Іншими словами, які самі конкретні елементи, які будуть представлені в базі знань? Повертаючись до компетенції питань, які ми визначили в Кроці 1 в Розділі 3, найбільш конкретні поняття, які будуть складати відповіді на ці питання є дуже хорошими кандидатами для фізичних осіб в базі знань.
Окремі екземпляри є найбільш конкретні поняття, представлені в базі знань.
Наприклад, якщо ми тільки будемо говорити про сполученні вино з їжею ми не будемо зацікавлені в конкретних фізичних пляшок вина. Тому такі терміни як Sterling Vineyards Merlot, ймовірно, буде найбільш специфічні терміни, які ми використовуємо. Тому, Стерлінг виноградники Merlot буде екземпляром в базі знань.
З іншого боку, якщо ми хочемо зберегти інвентаризацію вин в ресторані на додаток до бази знань хорошого вина їжі спарювань, окремі пляшки кожного вина можуть стати окремі випадки в нашій базі знань.
Точно так же, якби ми хотіли записати різні властивості для кожного конкретного врожаю в Sterling Vineyards Merlot, то питома марочні вина є екземпляром в базі знань і Sterling Vineyards Merlot є клас, який містить екземпляри для всіх своїх вин.
Інше правило може «перемістити» деякі окремі екземпляри в набір класів:
Якщо поняття формують природну ієрархію, то ми повинні представити їх у вигляді класів
Розглянемо винні області. Спочатку, ми можемо визначити основні винні регіони, такі як Франція, США, Німеччина і так далі, як класи і конкретних регіонах вина в цих великих регіонів як екземпляри. Наприклад, область Бургундія є екземпляром класу французького регіону. Проте, ми хотіли б також сказати, що регіон Кот д’Ор є регіоном Бургундії. Тому регіон Бургундія повинен бути класом (щоб мати підкласи або екземпляри). Проте, що робить регіон Бургундія клас і Кот д’Ор область примірника області Бургундія здається довільним: дуже важко чітко розрізняти, які регіони є класи і які є екземплярами. Тому ми визначаємо все винні області як класи. Prot�g�-2000 дозволяє користувачам визначити деякі класи як Абстрактні, показуючи, що клас не може мати будь-яких прямих примірників. У нашому випадку, всі класи є абстрактними область (Рисунок 8).
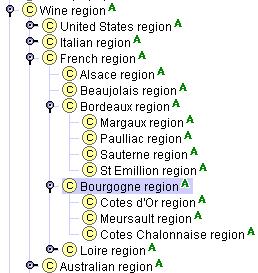
Рисунок 8. Ієрархія винних областей. “А” піктограмами, які класів показують, що класи є абстрактними і не може мати будь-яких прямих примірників.
Та ж ієрархія класів була б неправильно, якби ми опустили слово “область” від імен класів. Ми не можемо сказати, що клас Alsace є підкласом класу Франції: Ельзас не є свого роду у Франції. Проте, регіон Ельзас є свого роду французького регіону.
Тільки класи можуть бути організовані в ієрархії-представлення знань систем не мають поняття суб-екземпляра. Тому, якщо є природна ієрархія між термінами, такими як в термінологічних ієрархії з розділу 4.2, ми повинні визначити ці терміни як класи, навіть якщо вони не можуть мати будь-які екземпляри своїх власних.
4.7 Обмеження області
В якості останнього зауваження щодо визначення ієрархії класів, наступний набір правил завжди корисно при ухваленні рішення, коли визначення онтології завершена:
Онтологія не повинна містити всю можливу інформацію про домен: вам не потрібно спеціалізуватися (або узагальнювати) більше, ніж потрібно для вашої програми (не більше ніж один додатковий рівень в кожному напрямку).
Для нашого вина і їжі, наприклад, нам не потрібно знати, що папір використовується для етикеток або як приготувати креветки страви.
Аналогічним чином, онтологія не повинна містити всі можливі властивості і відмінності між класами в ієрархії.
У нашій онтології, ми, звичайно, не включають в себе всі властивості, які вино або продукти харчування могли б мати. Ми представляли найбільш істотні властивості класів елементів в нашій онтології. Незважаючи на те, винні українські книжки сказати нам розмір винограду, ми не включили ці знання. Точно так само ми не додали всі відносини, які можна собі уявити, серед всіх термінів в нашій системі. Наприклад, ми не включаємо такі відносини, як улюблене вино і улюбленої їжі в онтологію просто, щоб дозволити більш повне уявлення всіх взаємозв’язків між термінами ми визначили.
Останні правила також відноситься і до встановлення відносин між поняттями, які ми вже включили в онтологію. Розглянемо онтологію, що описує експерименти з біології. Онтологія, швидше за все, містить концепцію біологічних організмів. Вона також буде містити поняття Експериментатор, що виконує експеримент (з його ім’ям, аксесуари і т.д.). Це правда, що експериментатор, як людина, також відбувається біологічний організм. Проте, ми, ймовірно, не повинні включати ця різниця в онтології: з метою цього подання експериментатор не є біологічним організмом, і ми, ймовірно, ніколи проводити експерименти на самих експериментаторів. Якби ми представляли всі, що ми можемо сказати про класи в онтології, експериментатор стане підклас біологічного організму. Тим не менш, ми не повинні включати ці знання для передбачаються застосувань. Насправді, в тому числі і цей тип додаткової класифікації для існуючих класів насправді боляче: тепер екземпляр експериментатор матиме слоти для ваги, віку, видів і інших даних, що відносяться до біологічного організму, але абсолютно недоречні в контексті опису експерименту , Проте, ми повинні записати таке проектне рішення в документації на благо користувачів, які будуть дивитися на цій онтології і які можуть не знати про застосування ми мали на увазі.
4.8 Несумісні підкласи
Багато системи дозволяють явно вказати, що кілька класів несумісні. Класи несумісні, якщо вони не можуть мати будь-яких примірників загального. Наприклад, десертні вина і білі вина класи в нашій онтології не перетинаються: Є багато вина, які є екземплярами обох. Примірник Rothermel Trochenbierenauslese Рислінг класу Солодкий Рислінг є одним з таких прикладів. У той же час, Червоне вино і білі вина класи не перетинаються: не вино не може бути одночасно червоним і білим. Визначення того, що класи не перетинаються дозволяє системі перевірки онтологія краще. Якщо ми оголошуємо Червоне вино і Біле класи вина, щоб вони не перетиналися, а потім створити клас, який є підкласом як Riesling (підклас Білого вина) і порт (підклас Червоного вина), система може вказати, що є помилка моделювання.
5 Визначення властивостей — докладніше
У цьому розділі ми розглянемо ще кілька деталей, щоб мати на увазі при визначенні слотів в онтології (Крок 5 і Крок 6 в Розділі 3). В основному, ми обговорюємо зворотні слоти і значення за замовчуванням для слота.
5.1 Зворотні слоти
Значення слота може залежати від значення іншого слота. Наприклад, якщо вино було вироблено на винному заводі, то винний завод виробляє, що вино. Ці два відносини, виробник і виробляє, називаються зворотними відносинами. Зберігання інформації “в обох напрямках” є зайвим. Коли ми знаємо, що вино виготовляється на винному заводі, додаток, що використовує базу знань завжди може вивести значення для зворотного відносини, що виноробня виробляє вино. Проте, з точки зору набуття знань зручно мати обидві частини інформації в явному вигляді присутня. Такий підхід дозволяє користувачам заповнити вино в одному випадку і винний завод в інший. Система придбання знань може автоматично заповнити значення для зворотного відносини, які страхують узгодженість бази знань.
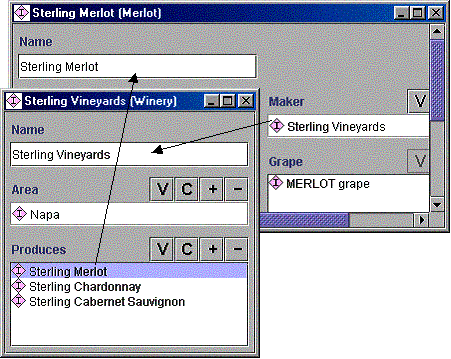
Рисунок 9. Примірники з зворотними слотами. Слот виробляє для класу винзавод є зворотною слот мейкера для класу Вино. Заповнення одного з слотів викликає автоматичне оновлення іншого.
5.2 Стандартні значення
Багато фреймових системи дозволяють задати такі значення за замовчуванням для слотів. Якщо конкретне значення слота однаково для більшості примірників класу, ми можемо визначити це значення буде стандартним значенням для слота. Потім, коли кожен новий екземпляр класу, що містить цей слот створюється, система заповнює значення за замовчуванням автоматично. Потім ми можемо змінити значення на будь-яке інше значення, яке гіперграні дозволить. Тобто, значення за замовчуванням існують для зручності: вони не застосовують жодних нових обмежень на моделі або змінити модель в будь-якому випадку.
Наприклад, якщо більшість вин ми будемо обговорювати повні вина, ми можемо мати “повний” в якості значення за замовчуванням для тіла вина. Тоді, якщо ми не сказати інакше, все вина, ми визначаємо буде насичене.
Зверніть увагу, що це відрізняється від значень слота. Значення слотів не можуть бути змінені. Наприклад, ми можемо сказати, що слот цукор має значення СОЛОДКЕ для класу десертного вина. Тоді все підкласи і екземпляри вина класу десерт матиме СОЛОДКЕ значення для слота цукру. Це значення не може бути змінено в будь-якому з підкласів або примірників класу.
6 Що містить назва?
Визначення угоди про імена для понять в онтології, а потім строго дотримуючись цих конвенцій не тільки робить онтологію легше зрозуміти, але і допомагає уникнути деяких поширених помилок моделювання. Є багато альтернатив в позначенні понять. Часто немає особливих причин, щоб вибрати ту чи іншу альтернативу. Проте, нам потрібно
Визначити правила іменування класів і слотів і приєднатися до нього.
Наступні особливості системи подання знань впливають на вибір іменування:
� Чи є у системи таке ж простір імен для класів, слотів і примірників? Тобто, це система дозволяє мати клас і слот з таким же ім’ям (наприклад, клас винний завод і слот винний завод)?
� Чи є система чутливий до регістру? Тобто, це система лікування імена, які відрізняються тільки в разі як різні назви (наприклад, Winery і винний завод)?
� Які роздільники працює система дозволяє в назвах? Тобто, можуть імена утримувати прогалини, коми, зірочки, і так далі?
Prot�g�-2000, наприклад, підтримує єдиний простір імен для всіх своїх кадрів. Він чутливий до регістру. Таким чином, ми не можемо мати клас винний завод і слот винний завод. Ми можемо, однак, є клас “Винний завод” (не в верхньому регістрі) і слот винний завод. КЛАСИЧНИЙ, з іншого боку, не чутливий до регістру і підтримує різні простору імен для класів, слотів і фізичних осіб. Таким чином, з точки зору системи, немає ніяких проблем в позначенні як клас і слот винний завод.
6.1 Капіталізація і роздільники
По-перше, ми можемо значно покращити читабельність онтології, якщо ми використовуємо послідовну капіталізацію для найменувань понять. Наприклад, він є загальним для своєї вигоди імена класів і використовувати нижній регістр для імен слотів (передбачається, що система чутлива до регістру).
Коли ім’я поняття містить більше одного слова (наприклад, звичайно їжі) ми повинні розмежувати слова. Ось деякі можливі варіанти.
� Використовуйте пробіл: Meal Course (багато систем, включно з Prot�g�, дозволяють пробіли в назвах понять).
� Виконайте слова разом і капіталізувати кожне нове слово: MealCourse
� Використовуйте підкреслення або тире або інший роздільник в ім’я: Meal_Course, Meal_course, Meal-Course, Meal-course. (Якщо ви використовуєте роздільники, вам також потрібно вирішити, чи буде чи ні капіталізуються кожне нове слово)
Якщо система подання знань дозволяє прогалини в іменах, їх використання може бути найбільш інтуїтивним рішенням для багатьох розробників онтологій. Це, однак, важливо враховувати й інші системи, з якими ваша система може взаємодіяти. Якщо ці системи не використовують прогалини або якщо ваша презентація середовище не обробляє прогалини добре, це може бути корисно використовувати інший метод.
6.2 Однина чи множина
Ім’я класу представляє собою колекцію об’єктів. Наприклад, клас Вино насправді представляє все вина. Таким чином, це може бути більш природним для деяких дизайнерів назвати вин класу, а не вина. Жодна альтернатива чи не краще або гірше, ніж інші (хоча особливої для імен класів частіше використовується на практиці). Проте, незалежно від вибору, вона повинна бути постійною протягом всієї онтології. Деякі системи навіть вимагають від своїх користувачів, щоб оголосити заздалегідь, чи буде чи ні вони збираються використовувати однини чи множини імен понять і не дозволяють їм відхилятися від цього вибору.
Використовуючи ту ж форму, весь час також запобігає проектувальника від таких помилок моделювання, як створення класу Вина, а потім створення класу Вино як його підкласу
(див. Розділ 4.1).
6.3 Умови вживання префіксів і суфіксів
Деякі методики бази знань пропонують використовувати префікс і суфікс угоди в іменах, щоб розрізняти класи і слоти. Дві загальні практики, щоб додати має- або суфікс -of до імен слотів. Таким чином, наші слоти стали має мейкером і має-виноробню, якщо ми вибрали має- конвенції. Щілини стають верстальник і виноробня через з, якщо ми вибрали офи- конвенції. Такий підхід дозволяє будь-якому дивитися на термін відразу ж визначити, чи є цей термін клас або слот. Проте, термін назви трохи довше стали.
6.4 Інші особливості назв
Ось ще кілька речей, які слід враховувати при визначенні правил іменування:
� Не додавайте такі рядки, як “клас”, “власність”, “Спорт у подробицях”, і так далі до найменувань понять.
Завжди ясно форма контекст чи поняття клас або слот, наприклад. Крім того є ви використовуєте різні угоди про імена для класів і слотів (скажімо, капіталізація і відсутність капіталізації відповідно), сама назва буде свідчити про те, що ця концепція.
� Це, як правило, хороша ідея, щоб уникнути скорочень в іменах понять (тобто, використовуйте “Каберне Совіньйон”, а не “Каб”)
� Імена прямих спадкоємців класу повинні або все включати чи не включати в себе ім’я суперкласу. Наприклад, якщо ми створюємо два підкласу класу Вино для подання червоних і білих вин, два імені підкласу повинні бути або червоне вино і біле вино або червоне і біле, але не червоне вино і білий.
7 Інші ресурси
Ми використовували Prot�g�-2000 як онтологія-розвивального середовища для наших прикладів. Дьюнвельд і його колеги (Дьюнвельд і ін. 2000) описують і порівняти ряд інших середовищ онтологій розвитку.
Ми спробували вирішити самі основи розвитку онтологій і не обговорювали багато з передових тим чи альтернативних методологій розробки онтологій. Г�мез-П�рез (Г�мез-П�рез 1998) і Ушольд (Ушольд і Грунінгер 1996) представляють альтернативні методології розвитку онтологій. Підручник “Онтолінгва” (Фарквхар 1997) обговорює деякі формальні аспекти моделювання знань.
В даний час дослідники підкреслюють не тільки розвиток онтології, а й онтологія аналіз. Як генеруються і повторно використовувати більше онтологій, більше інструментів будуть доступні для аналізу онтологій. Наприклад, Химера (Макгіннесс і ін. 2000) надає діагностичні інструменти для аналізу онтологій. Аналіз, який здійснює Chimaera включає в себе як перевірку логічної правильності онтології і діагностики найбільш поширених помилок проектування онтології. Дизайнер онтологія може знадобитися провести діагностику химера над економікою, що розвивається онтології для визначення відповідності загальних онтологічних-моделювання практики.
8 Висновки
У цьому керівництві ми описали методологію розробки онтології для декларативних каркасних систем на основі. Ми перерахували кроки в процесі розробки онтологій і вирішувати складні питання, пов’язані з визначенням ієрархії класів і властивостей класів і екземплярів. Проте, після того, як за всіма правилами і пропозиції, одне з найбільш важливих речей, щоб пам’ятати наступне: немає єдиної правильної онтології для будь-якого домену. Онтологія конструкція являє собою творчий процес, і ніякі дві онтології, розроблені різними людьми не було б те ж саме. Потенційні застосування онтології і розуміння дизайнера і зору області, безсумнівно, впливають на вибір дизайну онтологій. “Доказ знаходиться в пудингу” – ми може оцінити якість нашої онтології, тільки використовуючи її в додатках, для яких ми розробили його.
Подяка
Prot�g�-2000 (http://protege.stanford.edu) розроблено групою Марка Музена при відділі медичної інформатики Стенфорда. Ми створили кілька рисунків за допомогою плагіна OntoViz в Prot�g�-2000. Ми імпортували початкову версію онтології вин із бібліотеки онтологій Ontolingua (http://www.ksl.stanford.edu/software/ontolingua/), яка у свою чергу використовувала версію, випущену Брахманом і колегами (Брахман та ін. 1991) і представлену системою презентації знань CLASSIC. Потім ми модифікували онтологію уявити принципи концептуального-моделювання для декларативних онтологій фреймових. Розширені коментарі Рея Фергерсона та Мора Пелега до більш ранніх проектів значно покращили цю роботу.
Посилання
Бух Г., Румбау Дж. і Якобсон І. (1997). Керівництво користувача мови єдиного моделювання: Addison-Wesley.
Брахман Р.Дж., Макгіннес Д.Л., Патель-Шнайдер П.Ф., Реснік Л.А. і Боргіда A. (1991). Життя з CLASSIC: коли і як використовувати мову типу KL-ONE. Принципи семантичних мереж. Дж. Ф. Соуа, редактор, Морган Кауфманн: 401-456.
Бріклі Д. і Гуха Р.В. (1999). Специфікація схеми структури опису ресурсу (RDF). Пропонована рекомендація, консорціум World Wide Web Consortium: http://www.w3.org/TR/PR-rdf-schema.
Химера (2000). Середовище онтології химер. www.ksl.stanford.edu/software/chimaera
Дьюнвельд A.Дж., Стотер Р., Вайден M.Р., Кенепа Б. і Бенджамінс В.Р. (2000). WonderTools? Порівняльне вивчення засобів створення онтології. Міжнародний журнал людино-комп’ютерних досліджень 52(6): 1111-1133.
Фаркхар A. (1997). Довідник з Ontolingua. http://ksl-web.stanford.edu/people/axf/tutorial.pdf
Г�мез-П�рез A. (1998). Обмін знаннями і повторне їх використання. Довідник з прикладних експертних систем. Лібовітц, редактор, CRC Press.
Грубер Т.Р. (1993). Перекладацький підхід до специфікації портативної онтології. Набуття знань 5: 199-220.
Грунінгер M. і Фокс M.С. (1995). Методологія проектування та оцінки онтологій. У: Праці семінару з основних питань в онтологічних обміну знаннями, IJCAI-95, Монреаль.
Гендлег Дж. і Макгіннес Д.Л. (2000). Мова агента маркування DARPA. Інтелектуальні системи IEEE 16(6): 67-73.
Хамфріс Б.Л. і Ліндберг Д.A.Б. (1993). Проект UMLS: що робить концептуальну зв’язок між користувачами і необхідної їм інформації. Бюлетень Асоціації медичної бібліотеки 81(2): 170.
Макгіннес Д.Л., Абрахамс M.K., Реснік Л.A., Патель-Шнайдер П.Ф., Томасон Р.Х., Каваллі-Сфорца В. і Конаті C. (1994). Довідник із системи представлення знань Classic. http://www.bell-labs.com/project/classic/papers/ClassTut/ClassTut.html
Макгіннес Д.Л., Файкс Р., Райс Дж. і Уальдер С. (2000). Середовище для змішування та тестування великих онтологій. Принципи подання знань і висновків: праці сьомої міжнародної конференції (KR2000). A. Г. Кон, Ф. Гінчігліа та Б. Селман, редактори. Сан-Франциско, Каліфорнія, Morgan Kaufmann Publishers.
Макгіннес Д.Л. і Райт Дж. (1998). Концептуальне моделювання для конфігурації: заснований на логіці підхід до опису. Штучний інтелект для інженерного проектування, аналізу і виробництва – спеціальний випуск по конфігурації.
Мусен M.A. (1992). Розміри обміну знаннями та повторне використання. Комп’ютери та біомедичних досліджень 25: 435-467.
Ontolingua (1997). Довідник із системи Ontolingua. http://www-ksl-svc.stanford.edu:5915/doc/frame-editor/index.html
Прайс К. і Спекмен К. (2000). Клінічні терміни SNOMED. BJHC&IM – Британський журнал обчислень у сфері охорони здоров’я й управління інформацією 17(3): 27-31.
Protege (2000). Проект Protege. http://protege.stanford.edu
Рош E. (1978). Принципи категоризації. Пізнання і категоризація. Р. E. та Б.Б. Ллойд, редактори. Хіллсайд, Нью-Джерсі, Lawrence Erlbaum Publishers: 27-48.
Ротенфлу T.Р., Дженнарі Дж.Х., Ерікссон Х., Пуерта A.Р., Ту С.У. і Мусен M.A. (1996). Багаторазові онтології, засоби придбання знань і систем продуктивності: рішення PROT�G�-II до Sisyphus-2. Міжнародний журнал людино-комп’ютерних досліджень 44: 303-332.
Румбау Дж., Блаха M., Премерлані У., Едді Ф. і Лоренсен У. (1991). Об’єктно-орієнтоване моделювання та дизайн. Інглвуд Кліффс, Нью-Джерсі: Prentice Hall.
Ушольд M. і Грунінгер M. (1996). Онтології: принципи, методи та застосування. Огляд інженерії знань 11(2).
[1] Ми прописними буквами імена класів і імена, що починаються слот з низьким буквами. Ми також використовуємо Моноширинний шрифт для всіх термінів з прикладу онтології.
[2] Ми можемо також переглянути класи як унарні предикати-питання, які мають один аргумент. Наприклад, “Чи є цей об’єкт вино?» Унарні предикати (або класи) контрастують з бінарними предикатами (або слоти) -Питання, які мають два аргументи. Наприклад, “Чи є смак цього об’єкта сильним?” “Який аромат цього об’єкта?”
[3] Деякі системи просто вказати тип значення з класом, а не вимагає спеціальної заяви слотів типу примірника.
[4] Ми вирішили представити тільки червоні Порти в нашій онтології: білі порти існують, але вони вкрай рідкісні.
[5] При цьому ми вважаємо, що кожен анатомічний орган є класом, так як ми хотіли б, щоб говорити про “1-го лівого ребра Джона”. Окремі органи існуючих людей будуть представлені як люди в нашій онтології.